גלידות ואנגרמות
— Algorithms, Python — 8 min read
חידה:
הגעתי לחנות גלידה, אבל כיאה לחנות מחידת אלגוריתמים, החנות מתנהלת בצורה קצת מוזרה.
הקופאי מקבל הזמנות בפורמט ״טעם1, טעם2, ...״, כשיתכן שטעם אחד זהה לטעם אחר,
ומעביר אותן למכין הגלידות (להלן הגלידאי).
עד כאן די סטנדרטי, אבל הנה בא הקאץ׳:
הגלידאי יכול להרכיב גלידות רק ב״משיכה״ אחת.
אני אתן דוגמה. נניח שככה נראה ״שולחן הטעמים״ של הגלידאי:

הגלידאי יכול להכין את ההזמנה ״ענבים, קפה, וניל״ (וכל סדר אחר שלה, כמו ״קפה, וניל, ענבים״), כי אלה 3 טעמים סמוכים.
אבל ההזמנה ״וניל, מסטיק, בננה״ לא ברת-ביצוע, כי 3 הטעמים האלה לא סמוכים.
ההזמנה ״קפה, וניל, קפה, מסטיק״ גם אפשרית, אבל ההזמנה ״וניל, מסטיק, קפה, וניל״ לא, כי ב״שולחן הטעמים״ אין קטע באורך 4 טעמים שמכיל פעמיים את הטעם וניל.
המטרה שלנו היא לייעל את התהליך, ולבנות מערכת שהקופאי יוכל להזין לתוכה הזמנה, ולקבל מיד תשובה האם ההזמנה ברת-ביצוע או לא.
בואו נסתכל קצת אחרת על החידה. במקום להסתכל על ״שולחן הטעמים״ כרשימה של טעמים, נתרגם אותו למחרוזת. במקום כל טעם, יופיע התו הראשון בשם שלו.
יצא לנו נחמד כי כל טעם מתחיל באות יחודית, אבל קל לתרגם את הפתרון שאני אציג לפתרון שפועל על טעמים ממש ולא רק תווים.
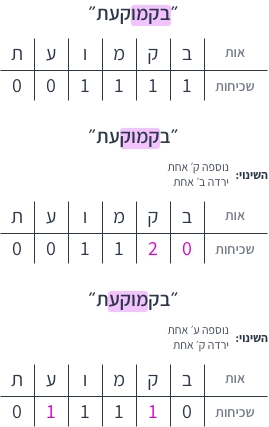
המחרוזת שמתארת את השולחן שבדוגמה, שנק�רא לה בהמשך tastes, היא:
1tastes = "בקמוקעת"באותו האופן נתייחס להזמנה כמחרוזת, וההזמנה ״קפה, וניל, קפה, מסטיק״ תתורגם למחרוזת:
1order = "קוקמ"וקיבלנו חידה עם ניחוח פחות מתוק, אבל יותר פשוטה להבנה.
אנחנו צריכים לכתוב אלגוריתם שבהינתן המחרוזות tastes ו-order מחזיר true אם ורק אם order או לפחות אחת מהאנגרמות שלה מוכלות ב-tastes.
אזכיר (או אחדש) שאנגרמה של מילה היא מילה חדשה שנוצרה משינוי סדר האותיות של .
הפתרון ה-brute forceי יהיה לחשב את כל הפרמוטציות (שם כולל למילה המקורית, והאנגרמות שלה) של order
ועבור כל אחת מהן לבדוק אם היא מוכלת ב-tastes. מה הסיבוכיות של הפתרון הזה?
נסמן את האורך של tastes ב- ושל order ב-.
הבדיקה האם פרמוטציה ספציפית של order מוכלת ב-tastes, במימוש הנפוץ, לוקחת .
ישנן פרמוטציות של order. לכן, הסיבוכיות של הפתרון היא , אקספוננציאלי ולא מגניב. אנחנו מסוגלים להרבה יותר טוב.
לצורך הפתרון נכיר את המושג ״היסטוגרמה״. היסטוגרמה של מילה היא טבלה שנותנת לכל תו ב- את מספר הפעמים שהוא מופיע בה.

מה שאנחנו בעצם צריכים לבדוק, זה האם קיימת ב-tastes תת-מחרוזת באורך של order שההיסטוגרמה שלה שווה להיסטוגרמה של order (כי שכיחות התווים של כל האנגרמות של מילה נתונה, זהה לשכיחות התווים במילה המקורית).
אז נכתוב קוד שעושה את זה באופן הכי פשוט בעולם, עובר על כל תת-מילה ב-tastes ומשווה את ההיסטוגרמה שלה להיסטוגרמה של order.
1def histogram_of(word: str) -> Dict[str, int]:2 histogram = {}3 for char in word:4 histogram[char] = histogram.get(char, 0) + 15 return histogram6
7
8def is_possible(tastes: str, order: str) -> bool:9 order_histogram = histogram_of(order)10 for substring_start_index in range(0, len(tastes) - len(order) + 1):11 substring = tastes[substring_start_index:substring_start_index + len(order)]12 if histogram_of(substring) == order_histogram:13 return True14 return Falseהסיבוכיות של הפעלה אחת של histogramOf היא כש- הוא אורך המחרוזת word.
isPossible עוברת על כל תתי-המחרוזות ב-tastes שבאורך של order.
יש סה״כ תת-מחרוזות כאלה, ומאחר וכל אחת מהן באורך , הסיבוכיות הכוללת של isPossible היא , שבפועל שווה ל- כי תמיד מתקיים .
זה שיפור מדהים מהפתרון הראשון שהצגנו, עכשיו זמן הריצה כבר לא אקספוננציאלי, אבל גם כאן, אנחנו מסוגלים ליותר.
אז בואו נבין בעצם איפה המקום לשיפור. אנחנו כן נהיה חייבים לסרוק את כל tastes בשביל להכריז על התשובה של isPossible, אבל לא בהכרח שנצטרך לבנות היסטוגרמה מאפס לכל תת-מילה חדשה.
נוכל לבנות רק את ההיסטוגרמה לתת-המחרוזת הראשונה, ובמעבר לתת-מחרוזת הבאה רק לתקן אותה באות החדשה שנוספה (להוסיף אחד לתא שלה בטבלה), והאות האחרת שהוצאה (לחסר אחד מהתא שלה בטבלה).
עדכון כזה של ההיסטוגרמה קורה ב-2 פעולות, כלומר, בזמן קבוע!
ההפעלה תראה ככה:
אבל עדיין הסיבוכיות תישאר אותה סיבוכיות, כי לכל תת-מחרוזת, אנחנו צריכים להשוות בין ההיסטוגרמה הנוכחית להיסטוגרמה של order, וזה קורה בסיבוכיות לינארית ביחס למספר הערכים בהיסטוגרמה הקטנה מביניהן.
הצלחנו להאיץ את תהליך בניית ההיסטוגרמה של תת-המילה הנוכחית. אנחנו יכולים להאיץ גם את הבדיקה.
הערכים היחידים שמשתנים משלב לשלב, הם הערכים של האות שנוספה והאות שחוסרה.
אנחנו יכולים לשמור counter שיספור את כמות אותיות שהערך שלהן בהיסטוגרמה של תת-המחרוזת הנוכחית שווה לערך שלהן בהיסטוגרמה של order.
אם האות שהוצאנו עכשיו הפרה את האיזון, נחסר מה-counter אחד,
אם היא הביאה לאיזון, נוסיף לו אחד. ככה גם לאות החדשה שנכנסה ל״חלון״ תת-המחרוזות.
אם ה-counter הגיע למספר האותיות בהיסטוגרמה של order, מצאנו התאמה, כי כל האותיות מתאימות וההיסטוגרמות זהות!
נראה את זה בקוד:
1def is_possible(tastes: str, order: str) -> bool:2 order_histogram = histogram_of(order)3 total_num_of_chars = len(order_histogram.keys())4
5 order_len = len(order)6 tastes_len = len(tastes)7
8 substring_histogram = histogram_of(tastes[0:order_len])9 matching_chars = sum(10 1 if value == order_histogram.get(char) else 011 for char, value in substring_histogram.items()12 )13
14 def update_char_in_histogram(char: str, offset: int):15 nonlocal matching_chars16 if substring_histogram.get(char) == order_histogram.get(char, 0):17 matching_chars -= 118 substring_histogram[char] = substring_histogram.get(char, 0) + offset19 if substring_histogram[char] == order_histogram.get(char, 0):20 matching_chars += 121
22 for substring_start_index in range(0, tastes_len - order_len + 1):23 if matching_chars == total_num_of_chars:24 return True25
26 if substring_start_index + order_len < tastes_len:27 new_letter = tastes[substring_start_index + order_len]28 update_char_in_histogram(new_letter, +1)29 dropped_letter = tastes[substring_start_index]30 update_char_in_histogram(dropped_letter, -1)31
32 return Falseהקוד מדבר בעד עצמו, רק חשוב לי לציין מה זה ה-nonlocal המוזר הזה שנמצא בשורה 15. בלי השורה הזאת, השורות 17 ו-20, היו מתפרשות כ-״תגדיר משתנה חדש
בשם matching_chars ותכניס לתוכו את הערך של matching_chars פחות/ועוד
1״.
זה לא בסדר משתי סיבות. הראשונה היא שאנחנו לא רוצים להגדיר משתנה חדש, אנחנו רוצים להשתמש בזה שב-scope החיצוני ולערוך אותו.
הסיבה השנייה היא שזה לא יתקמפל. הקומפיילר (כןכן יש קומפיילר ל-Python) יגיד שאנחנו מנסים לקבל את הערך של matching_chars עוד לפני שהגדרנו אותו, ותחת ההנחה שלו שאנחנו מגדירים בשורה הזאת משתנה חדש – הוא מאוד צודק.
ממה זה נובע? מזה שלהגדרת משתנה חדש, ולהשמה לתוך משתנה קיים יש syntax זהה. ב-Kotlin/Java, כדוגמה, זה לא היה קורה.
אז הוספנו את השורה שאומרת ״אנחנו מתכוונים למשתנה matching_chars הקיים, ולא לאחד חדש לוקאלי שיכולת לחשוב שאנחנו רוצים ליצור״.
ופתרנו את החידה! או שלא? מתחבא פה באג.
המחרוזת "b" כן מופיעה ב-"ab". אבל הפתרון שלנו יניב False.
לעומת זאת, המחרוזת "cd" לא מופיעה ב- "abc", אבל הפתרון שלנו יניב True.
למה? אחרי כל עדכון של substring_histogram ושל ה-counter, אנחנו משווים אותו ל-total_num_of_chars במטרה לבדוק אם ההיסטוגרמה של תת-המחרוזת הנוכחית זהה להיסטוגרמה של order.
אנחנו מחזירים True ברגע שמספר התווים שהערך שלהם ב-substring_histogram שווה לערך שלהם ב-order_histogram – שווה למספר התווים הכולל ב-order.
בדוגמה הראשונה, אנחנו מתחילים עם היסטוגרמה שהערך היחיד בה הוא a=1.
אחרי שאנחנו מתקדמים אות ימינה, אנחנו מחסרים 1 מהערך של a, ואז באמת כמות ה-a ב-substring_histogram שווה לכמות ה-a ב-order_histogram (בשתי ההיסטוגרמות, הערך של a הוא 0). אז אנחנו מגדילים את ה-counter.
באותה פעולה של תזוזת אות ימינה, אנחנו מוסיפים 1 לערך של b ב-substring_histogram. גם פה הערך של b זהה בשתי ההיסטוגרמות, אז נגדיל עוד פעם את ה-counter.
בשלב הזה,יש 2 תווים ב-substring_histogram שהערכים שלהם זהים לערכים בהיסטוגרמה של order. אבל יש רק אות אחת ב-order, אז total_num_of_chars, ששווה ל-1, לא יהיה שווה ל-counter.
אז הייתי יכולה לבוא ולהגיד: ״אז פשוט נבדוק אם matching_chars שווה או גדול מ-total_num_of_chars״, וזה באמת היה מתקן את התוצאה של is_possible("ab", "b").
אבל הפתרון שלנו עדיין היה אומר ״כן, אחת הפרמוטציות של "cd" מוכלת ב-"abc"״, מה שכמובן לא נכון.
ההתנהגות הזאת קורה כי אנחנו מתחילים עם ההיסטוגרמה a=1,b=1. במעבר של אות ימינה, נחסר מ-a 1, ונקבל שעכשיו מספר ה-a בתת-המחרוזת זהה למספר ה-a ב-order (0 בשתיהן), ולכן נגדיל את matching_chars. אחרי שנעדכן גם את הערך של c, נקבל שגם פה הערכים של התו בשתי הההיסטוגרמות זהים, ולכן נגדיל עוד פעם את matching_chars, שעכשיו שווה ל-2, בדיוק כמו מספר התווים ב-order. נכון שהערכים של שני תווים מתאימים, אבל אנחנו צריכים שגם הערך של d יתאים.
נפתור את זה בעזרת תחזוקה של הערך total_num_of_chars. בכל פעם שנוסיף אות חדשה ל-substring_histogram נגדיל את total_num_of_chars, ונדאג שגם הערך של האות הזה יבדק.
אנחנו צריכים לשנות כמה דברים. בתור התחלה, נאתחל את substring_histogram ככה שיכיל 0 לכל תו שמופיע ב-order אבל לא בתת-המחרוזת הראשונה של tastes. את total_num_of_chars נאתחל להיות כמות התווים בהגדרה החדשה של substring_histogram. והשינוי האחרון, הוא שבכל פעם שאנחנו מוסיפים ל-substring_histogram ערך חדש, נגדיל את total_num_of_chars ככה שיכיל את הגודל החדש של substring_histogram.
ככה יראה הקוד החדש:
1def is_possible(tastes: str, order: str) -> bool:2 order_histogram = histogram_of(order)3
4 order_len = len(order)5 tastes_len = len(tastes)6
7 substring_histogram = {8 **{char: 0 for char in order_histogram.keys()},9 **histogram_of(tastes[0:order_len])10 }11 total_num_of_chars = len(substring_histogram.keys())12 matching_chars = sum(13 1 if value == order_histogram.get(char) else 014 for char, value in substring_histogram.items()15 )16
17 def update_char_in_histogram(char: str, offset: int):18 nonlocal matching_chars19 nonlocal total_num_of_chars20 if char not in substring_histogram: 21 total_num_of_chars += 122 if substring_histogram.get(char) == order_histogram.get(char, 0):23 matching_chars -= 124 substring_histogram[char] = substring_histogram.get(char, 0) + offset25 if substring_histogram[char] == order_histogram.get(char, 0):26 matching_chars += 127
28 for substring_start_index in range(0, tastes_len - order_len + 1):29 if matching_chars == total_num_of_chars:30 return True31
32 if substring_start_index + order_len < tastes_len:33 new_letter = tastes[substring_start_index + order_len]34 update_char_in_histogram(new_letter, +1)35 dropped_letter = tastes[substring_start_index]36 update_char_in_histogram(dropped_letter, -1)37
38 return Falseאנחנו עושים פה עבודה מיותרת. תכונה מעניינת ולא טריוויאלית שיש ל-dictionaries ב-Python היא שאפשר לחשב את האורך שלהם ב-. זה קורה באופן דומה למה שכתבנו מפורשות בקוד, לכל dict נשמר size שמתעדכן בהוספה של ערך חדש. אז אנחנו יכולים לוותר על total_num_of_chars, ולהשתמש ב-len(substring_histogram) במקום. ככה זה יראה:
1def is_possible(tastes: str, order: str) -> bool:2 order_histogram = histogram_of(order)3
4 substring_histogram = {5 **{char: 0 for char in order_histogram.keys()},6 **histogram_of(tastes[0:len(order)])7 }8 matching_chars = sum(9 1 if value == order_histogram.get(char) else 010 for char, value in substring_histogram.items()11 )12
13 def update_char_in_histogram(char: str, offset: int):14 nonlocal matching_chars15 if substring_histogram.get(char) == order_histogram.get(char, 0):16 matching_chars -= 117 substring_histogram[char] = substring_histogram.get(char, 0) + offset18 if substring_histogram[char] == order_histogram.get(char, 0):19 matching_chars += 120
21 for substring_start_index in range(0, len(tastes) - len(order) + 1):22 if matching_chars == len(substring_histogram):23 return True24
25 if substring_start_index + len(order) < len(tastes):26 new_letter = tastes[substring_start_index + len(order)]27 update_char_in_histogram(new_letter, +1)28 dropped_letter = tastes[substring_start_index]29 update_char_in_histogram(dropped_letter, -1)30
31 return Falseוהגענו לפתרון שיעשה את הגלידאי (מהחידה המקורית, למקרה וכבר הספקתם לשכוח על מה מדובר) הרבה יותר מאושר! 🥳
מבוסס על החידה הזאת.